Homotopy OpTimization ML (HOTML) and DeepHOTML detectors
The archive provided in this page contains ready-to-use binaries and MATLAB functions for the HOTML and DeepHOTML detectors. The binaries and functions can be freely distributed for academic or personal use. Please contact the authors if you intend to employ the binaries or functions in the archive for commercial purpose.
Source Code
The HOTML detector is written using MATLAB; the DeepHOTML network is written using the tensorflow package and tested using MATLAB.
The source codes can be found in GitHub.
DeepHOTML Detector
The maximum-likelihood (ML) MIMO detection problem with binary constellation is given by
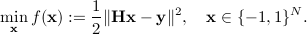
The two building blocks leading to our methods for handling the ML detection problem above are a homotopy transformation and an efficient first-order method.
First, we transform the ML problem as
![begin{aligned} min_{mathbf x } f(mathbf x)-lambda | mathbf x |^2,quad mathbf x in [ -1,1 ]^N end{aligned}](eqs/3205468236848351013-120.png)
with a parameter 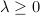 .
For
.
For 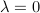 , the problem is a convex relaxation of the ML problem (easy to solve); for a larger
, the problem is a convex relaxation of the ML problem (easy to solve); for a larger 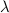 , the problem is, intuitively, closer to the ML problem but is more non-convex (harder to solve).
The idea of homotopy optimization is to try to find the ML solution by trying to trace the solution path of a sequence of the transformed
problems, from small to large .
, the problem is, intuitively, closer to the ML problem but is more non-convex (harder to solve).
The idea of homotopy optimization is to try to find the ML solution by trying to trace the solution path of a sequence of the transformed
problems, from small to large .
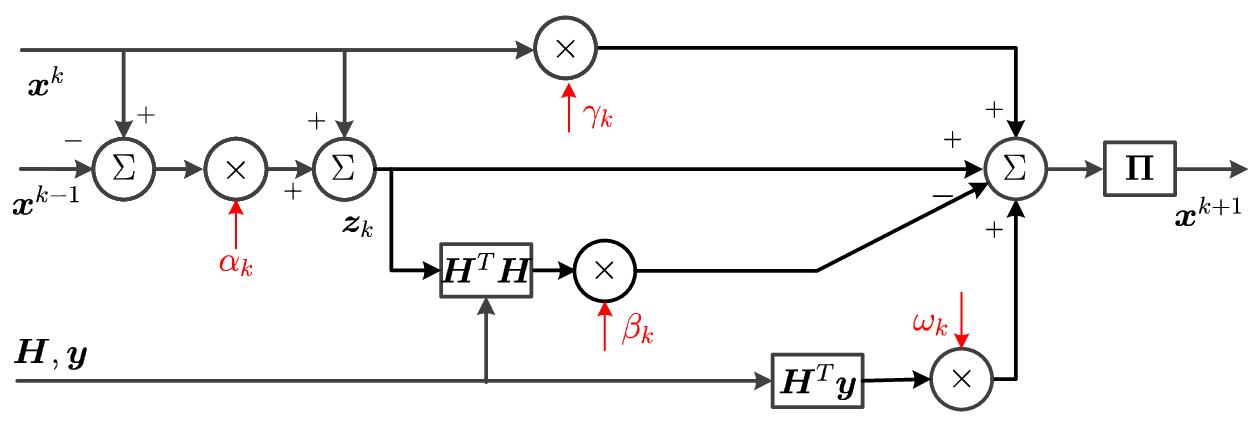
Second, the homotopy-transformed problem is handled by an efficient first-order method and its deep-unfolded adpatation — named HOTML and DeepHOTML, respectively. HOTML employs a combination of majorization-minimization and the accelerated projected gradient method. Simply speaking, it takes a recursive form
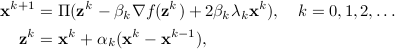
where 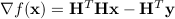 is the gradient of
is the gradient of 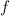 ,
,  is the projection onto
is the projection onto ![[-1,1]^N](eqs/7220646983027292699-120.png) ,
, 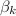 is a step size,
is a step size, 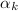 is an extrapolation coefficient, and
is an extrapolation coefficient, and 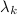 increases gradually.
DeepHOTML maps the iterations of HOTML as layers of a deep neural network, with the homotopy parameter and several other parameters (e.g.,
increases gradually.
DeepHOTML maps the iterations of HOTML as layers of a deep neural network, with the homotopy parameter and several other parameters (e.g., 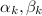 ) learnt from training data.
The following diagram shows one layer of the DeepHOTML network, with four scalar trainable parameters marked as
) learnt from training data.
The following diagram shows one layer of the DeepHOTML network, with four scalar trainable parameters marked as  .
.
 |
The DeepHOTML/HOTML can also handle the one-bit ML MIMO detection problem; that is, the received signal 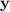 is one-bit quantized.
For more details, please see the following paper
is one-bit quantized.
For more details, please see the following paper
Mingjie Shao and Wing-Kin Ma, “Binary MIMO Detection via Homotopy Optimization and Its Deep Adaptation,” IEEE Trans. Signal Process., vol. 69, pp. 781-796, 2021. [PDF]
Simulations
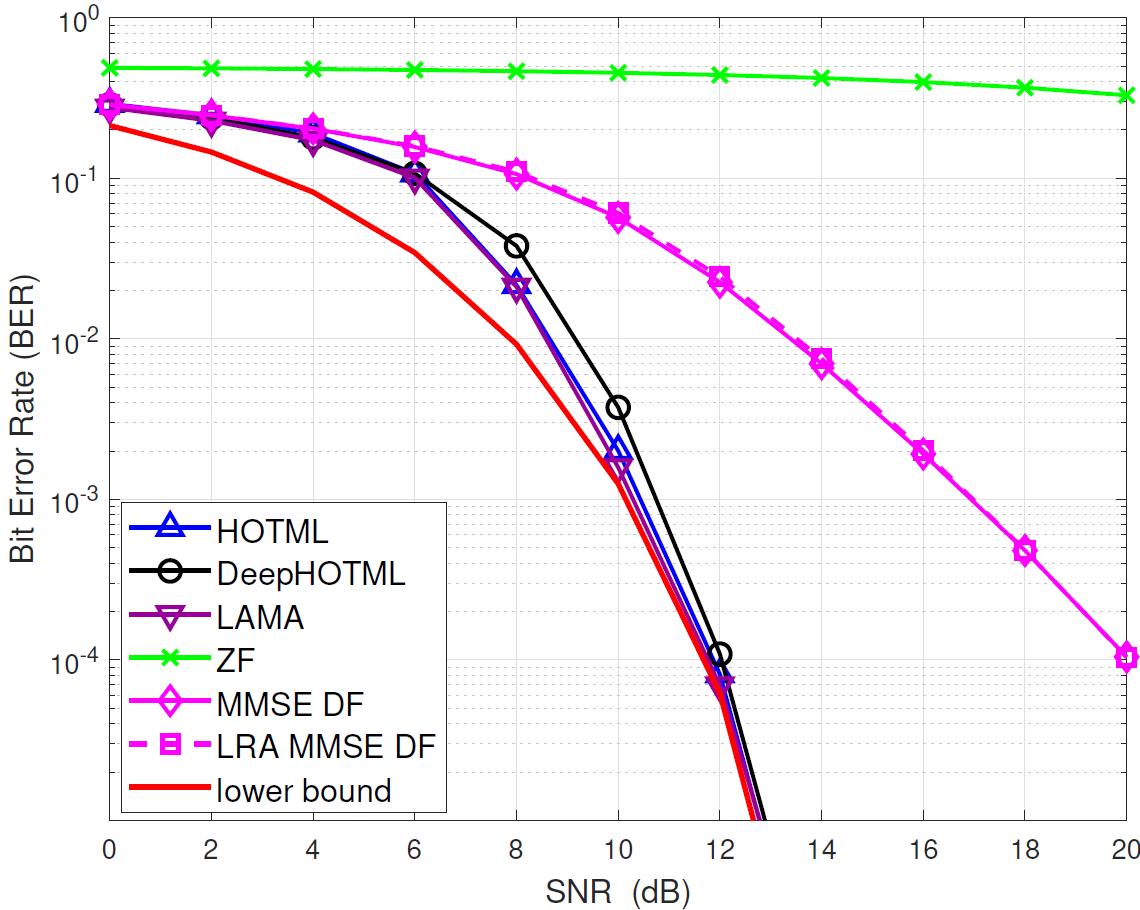
We demonstrate the performance of the DeepHOTML/HOTML detector for different problem sizes (in real dimension).
In the figures below,
'ZF’ denotes the zero-forcing detector,
'MMSE DF’ denotes the minimum-mean-square-error decision-feedback detector,
'LRA MMSE DF’ denotes the lattice reduction-aided MMSE DF detector,
'SD’ denotes the sphere decoder with Schnorr-Euchner implementation,
'SDR’ denotes the semidefinite relaxation, implemented by the row-by-row method,
'DetNet’ denotes the detection network, see here,
'LAMA’ denotes the large MIMO approximate message passing, see here.
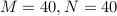
 |
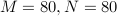
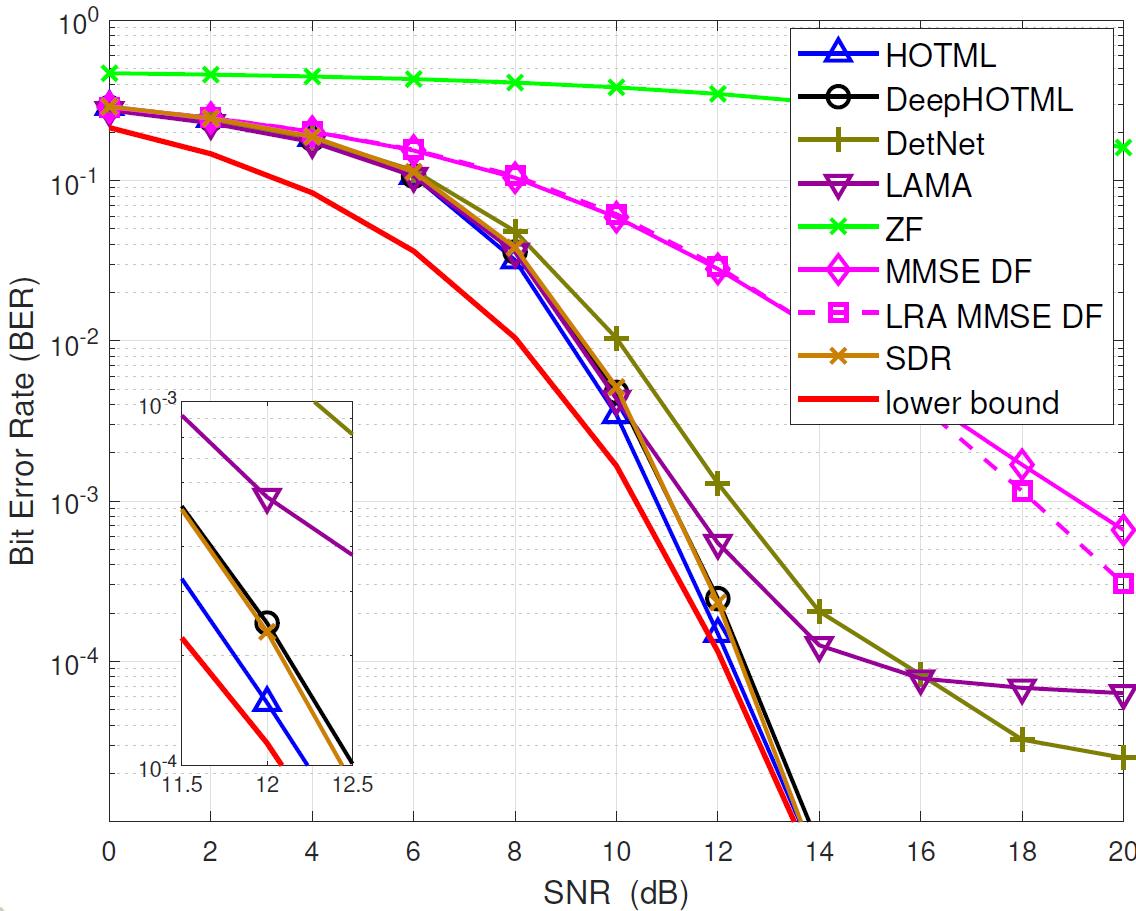 |
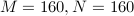
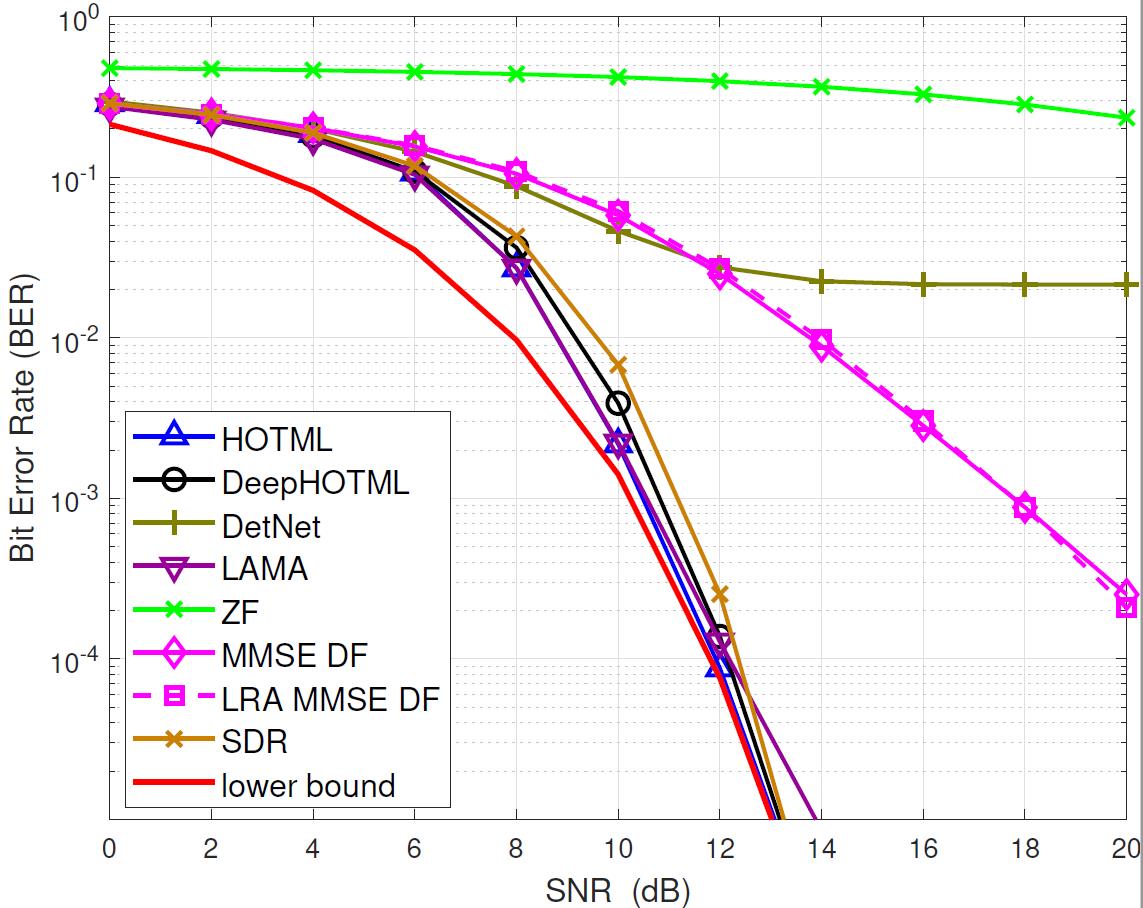 |
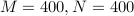
 |