 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
Xiaogang Wang and Eric Grimson
The task of this work is to discover objects from a collection of images. As shown in Figure 1, there are different classes of objects, such as cows, cars, faces, grasses, sky, bicycles, etc., in the image set. And an image usually contains several objects of different classes. The goal is to segment objects from images, and at the same time, to label these segments as different object classes in an unsupervised way (without any human labeling effort on image pixels or image captions). This integrates object segmentation and recognition. In our approach images are divided into local patches. A local descriptor is computed for each image patch and quantized into a visual word. Using topic models, the visual words are clustered into topics which correspond to object classes. Thus an image patch can be labeled as one of the object classes.
|
|
|
|
|
|
|
|
|
|
Figure 1. Given a collection of images as shown in the first row (which are selected from MSRC image dataset [1]), the goal is to segment images into objects and cluster these objects into different classes as shown in the second row.
Latent Dirichlet Allocation (LDA) [2] is a popular topic to solve this problem. Usually images are treated as documents and image patches are treated as words. It classes image patches into different object classes [2]. It assumes that if two types of patches are from the same object class, they often appear in the same images. However directly borrowing a language model to solve vision problems leads to some problems:

Figure 2. There will be some problems (see text) if the whole image is treated as one document when using LDA to discover classes of objects.
We propose a Spatial Latent Dirichlet Allocation (SLDA) model which encodes the spatial structure among visual words. It clusters visual words (e.g. an eye patch and a nose patch), which often occur in the same images and are close in space, into one topic (e.g. face). This is a more proper assumption for solving many vision problems when images often contain several objects. It is also easy for SLDA to model activities and human actions by encoding temporal information. It is different from LDA from several aspects:
See more details about SLDA in [3].
We test LDA and SLDA on the MSRC image dataset [1] with 240 images. In Figure 3, we show some examples of results using LDA and SLDA. Colors are used indicate different topics. The results of LDA are noisy and within one image most of the patches are labeled as one topic. SLDA achieves much better results than LDA. The results are smoother and objects are well segmented.
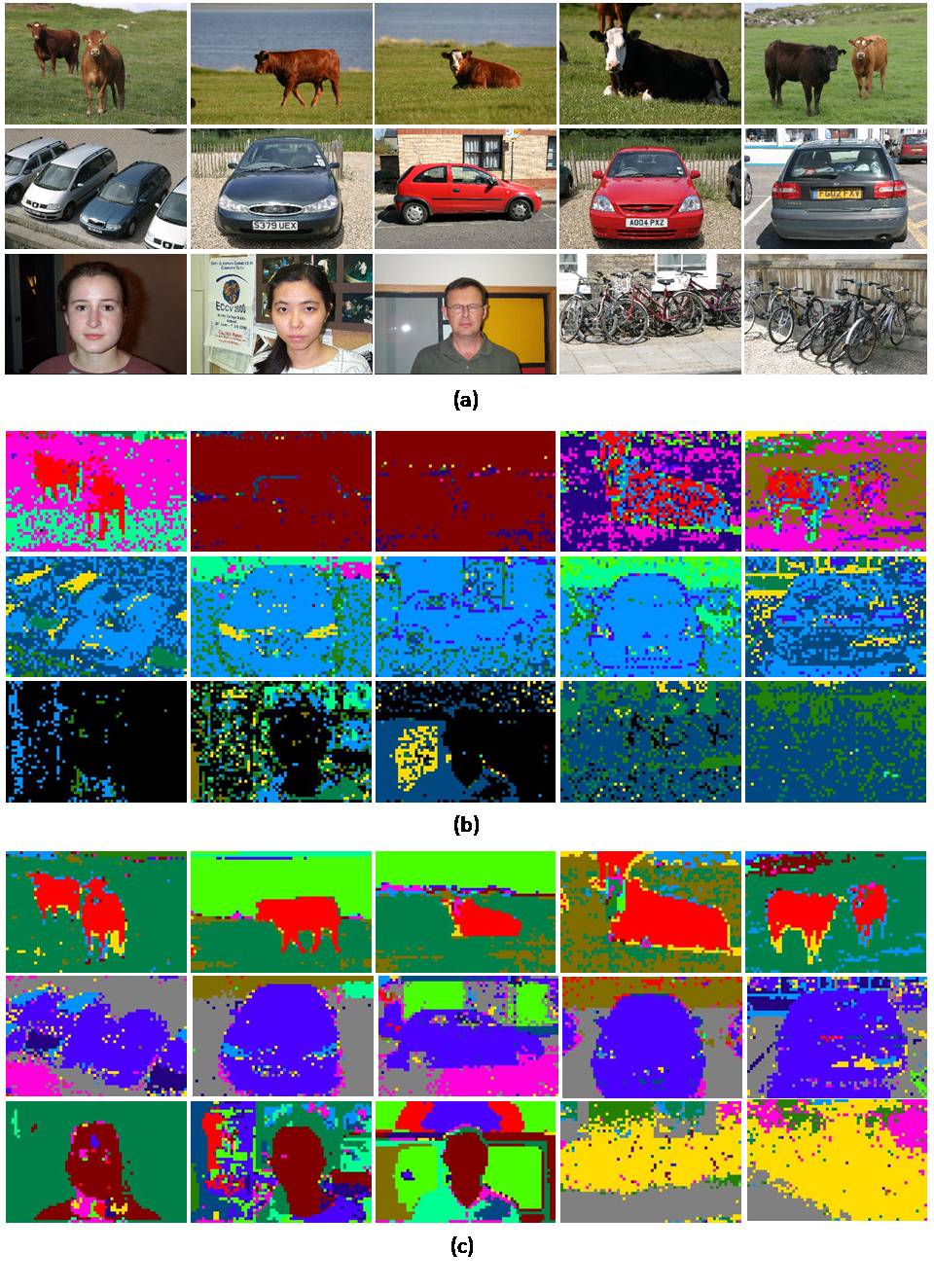
Figure 3. Examples of experimetnal results on MSRC image data set. (a): original images; (b): LDA results; (c) SLDA results.
The two models are also tested on a tiger video sequence with 252 frames. We treat all the frames in the sequence as an image collection and ignore their temporal order. Figure 4 shows their results on two sampled frames. We have a supplementary video material showing the results of the whole sequence. Using LDA, usually there are one or two dominant topics distributed like noise in a frame. Topics change as the video background changes. LDA cannot segment out any objects. SLDA clusters image patches into tigers, rock, water, and grass. If we choose the topic of tiger, as shown in the last row of Figure 4, all the tigers in the video can be segmented out. See the video result here. (The provided video is compressed with XviD MPEG-4 Codec. To install the Xvid codec, you can download codec from ffdshow-tryouts (http://ffdshow-tryout.sourceforge.net/) or www.xvid.org.)
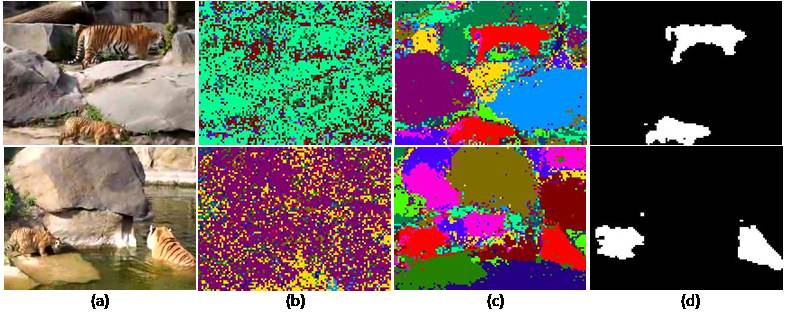
Figure 4. Discovering objects from a video sequence. The first column shows two fames in the video sequence. In the second column, we label the patches in the two frames as different topics using LDA. The thrid column plots the topic labels using SLDA. The red color indicates the topic of tigers. In the fourth column, we segment tigers out by choosing all the patches of the topic marked by red color. Please see the result of the whole video sequence in our supplementary video.
[1] J. Winn, A. Criminisi, and T. Minka. Object categorization by learned universal visual dictionary. In Proc. ICCV, 2005.
[2] J. Sivic, B. C. Russell, A. A. Efros, A. Zisserman, and W. T. Freeman. Discovering object categories in image collections. In Proc. ICCV, 2005.
[3] X. Wang and E. Grimson, “Spatial Latent Dirichlet Allocation,” in Proceedings of Neural Information Processing Systems Conference (NIPS) 2007. [PDF]