End-to-End Deep Learning for Person Search

Paper
Code
Dataset is available upon request (sli [at] ee.cuhk.edu.hk).
Abstract
Existing person re-identification (re-id) benchmarks and algorithms mainly focus on matching cropped pedestrian images between queries and candidates. However, it is different from real-world scenarios where the annotations of pedestrian bounding boxes are unavailable and the target person needs to be found from whole images. To close the gap, we investigate how to localize and match query persons from the scene images without relying on the annotations of candidate boxes. Instead of breaking it down into two separate tasks---pedestrian detection and person re-id, we propose an end-to-end deep learning framework to jointly handle both tasks. A random sampling softmax loss is proposed to effectively train the model under the supervision of sparse and unbalanced labels. On the other hand, existing benchmarks are small in scale and the samples are collected from a few fixed camera views with low scene diversities. To address this issue, we collect a large-scale and scene-diversified person search dataset, which contains 18,184 images, 8,432 persons, and 99,809 annotated bounding boxes. We evaluate our approach and other baselines on the proposed dataset, and study the influence of various factors. Experiments show that our method achieves the best result.
Contribution Highlights
- We propose an end-to-end deep learning framework to search for the query persons from whole images in the gallery, which is much closer to real applications. Instead of simply combining the pedestrian detector and person re-id, we jointly optimize these two objectives in a unitary process.
Several training strategies are proposed to effectively train the model and the experimental results show that our framework outperforms other baselines.
- We collect a large-scale benchmark dataset for person search, covering hundreds of scenes from street and movie snapshots. Rich annotations and protocols are also provided to facilitate the experiments on training and testing the models. The dataset and codes will be released to the public.
- A full set of benchmark is established on our dataset, which consists of the performance of our method, as well as other pedestrian detection and person re-id baselines. We also study the influence of various factors empirically, including detection recall, gallery size, occlusion and resolution.
A New Benchmark for Person Search
The dataset is a large scale benchmark for person search, containing 18,184 images and 8,432 identities.
Different from previous re-id benchmarks, matching query persons with manually cropped pedestrians, our dataset is much closer to real application scenarios by searching person from whole images in the gallery.
The dataset can be divided into two parts according to the image sources: street snap and movie.
In street snap, images were collected with hand-held cameras across hundreds of scenes and tried to include variations of view-points, lighting, resolutions, occlusions, and background as much as possible.
We choose movies and TV dramas as another source for collecting images, because they provide more diversified scenes and more challenging viewpoints.
1) Train and Test
We provide annotations for both person re-identification and pedestrian detection.
Each query person appears in at least two images and each image may contain more than one query persons and many more background persons. The data is partitioned into a training set and a test set. The training set contains 11,206 images and 5,532 query persons while the test set contains 6,978 images and 2,900 query persons.
2) Subsets
Two subsets, Low-resolution subset and Occlusion subset, are also released for evaluating the influence of various factors on person search.
The Low-resolution samples are selected by taking 10% queries with the smallest heights of the 2,900 test persons.
And the occlusion subset is composed of persons whose occlusion larger than 40%.

Examples of cropped images of query persons. (a) Examples with high resolution without occlusion. (b) Examples from the occlusion subset. (c) Examples from the low-resolution subset.
Each of (a)-(c) has two rows. The top row is from street snap and the bottom is from movies and TV dramas.
(a) (b) (c)
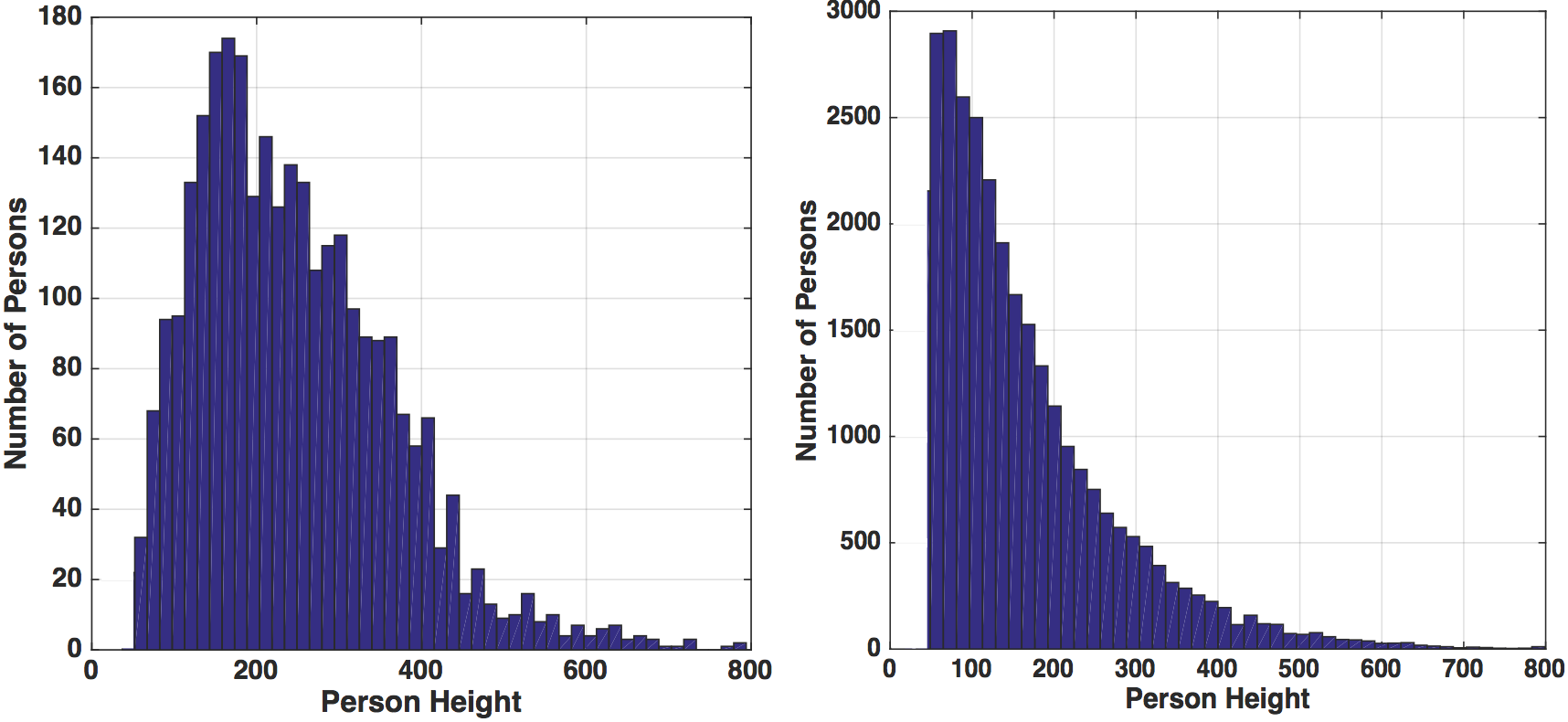
Distributions of the heights of test persons and background persons in test images. We only annotated pedestrians higher than 50 pixels. The heights of persons spread in a large range. The selected query persons generally appear in larger sizes than background persons.
(a) (b)
Method and Performance
1) Model Structure
To address the problem of person search, we propose an end-to-end deep learning framework which jointly handles the pedestrian detection and the person re-identification. As shown in Fig.1, the framework consists of three parts. First, we utilize a fully convolutional neural network (FCN) to extract feature maps from an input image of arbitrary size. Then, a pedestrian proposal network is built on the top of the feature maps to predict pedestrian bounding boxes. At last, for each confident candidate box, we use the ROI pooling technique to pool a fixed-length feature vector inside its region on the convolutional feature maps, followed by several fully connected layers to produce the final feature vector for re-id. By sharing the FCN for pedestrian detection and re-id feature extraction, we could accelerate the person search process. In the following, we will describe the network structure, as well as the training and test procedures.
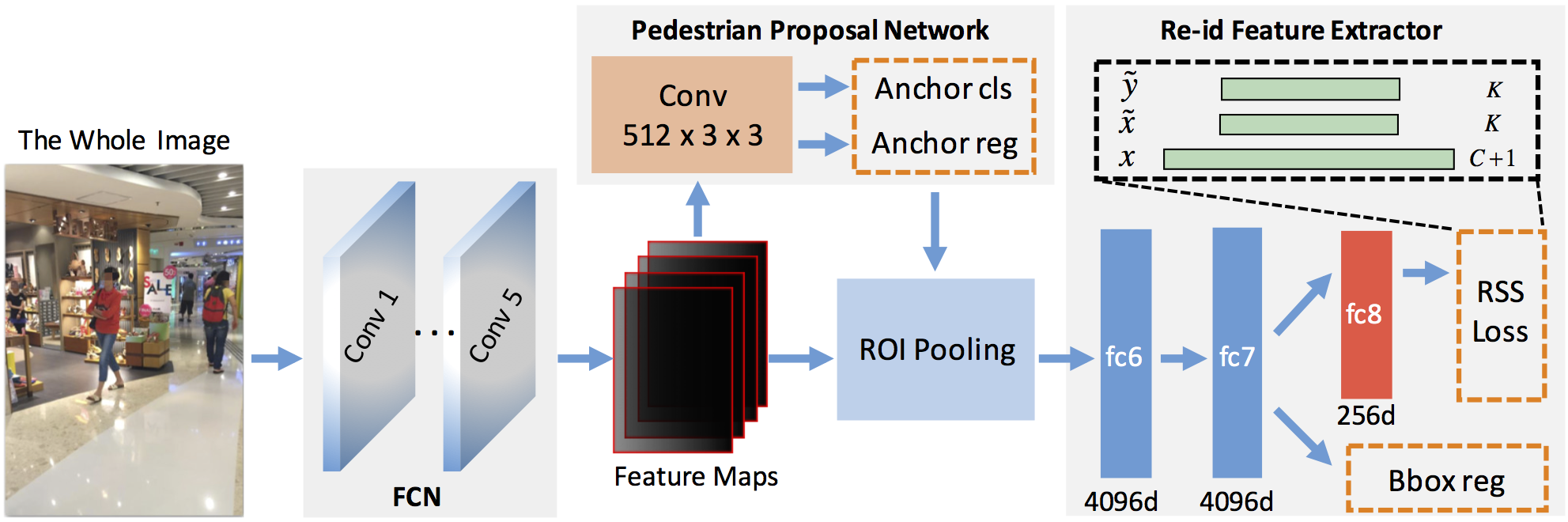
Fig.1. Overview of our framework. Given a whole image, we first utilize a fully convolutional network to extract feature maps. Then we deploy a convolution layer with 512×3×3 filters on the top of the feature maps, followed by sibling anchor classification (denoted by Anchor cls) and regression layers (denoted by Anchor reg) to predict pedestrian ROIs. These ROIs are then used to pool the feature vector for each candidate box on the convolutional feature maps. Three fully connected layers are utilized to produce the final feature vector (fc8) for computing distances. The boxes with dashed orange borders represent the loss layers.
2) Evaluation
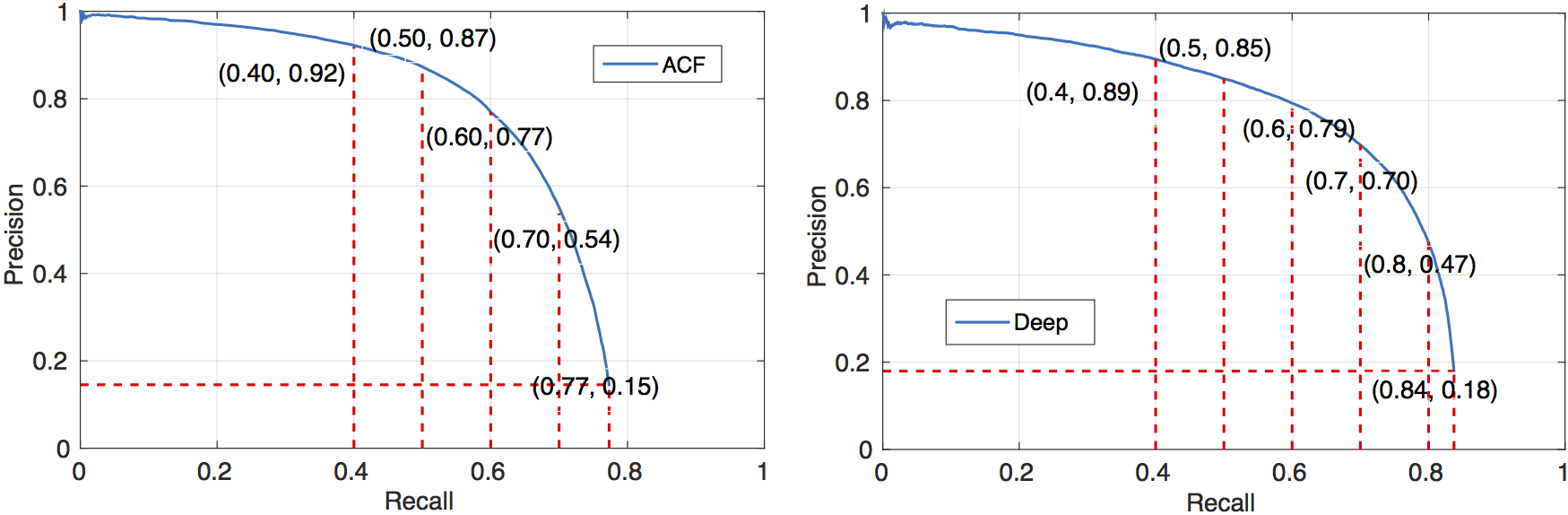
The precision-recall curves of the ACF and the Deep pedestrian detectors on our test set. Some (recall, precision) data points are annotated on the curves.

Comparisons between our approach and four person re-identification methods under two pedestrian detectors (ACF and Deep), as well as the ground truth boxes (GT).
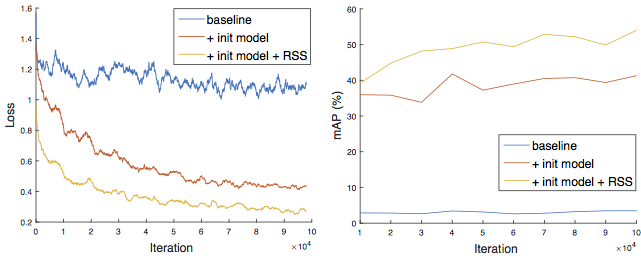
Training loss and test mAP of different models used in ablation experiments.
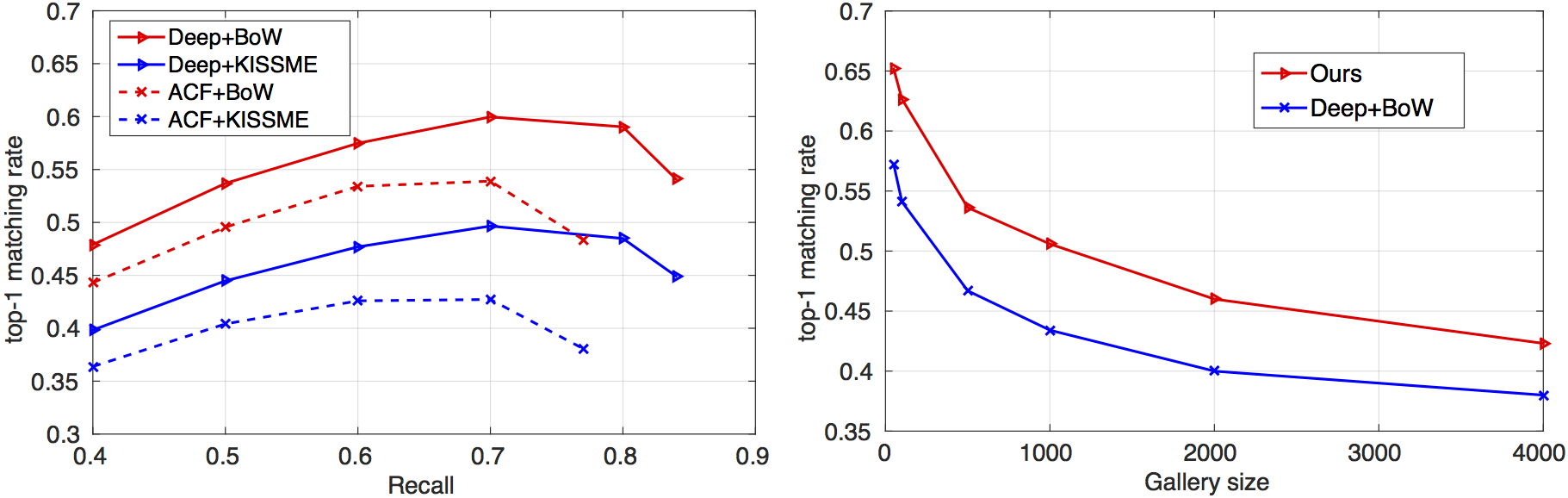
The top-k matching rates of (a) four baseline methods under different detection recalls, (b) our method and Deep+BoW with different gallery sizes.
(a) (b)
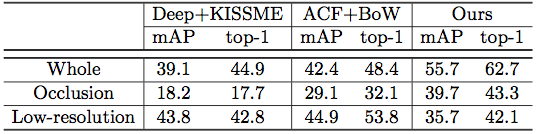
Experimental results of our algorithm and two combinations of detectors and person re-identification on the occlusion subset, low-resolution subset, and the whole test set.
3) Person Search Results
Fig.2 shows the person search results of the proposed method.

(a) (b)
Fig.2. (a) Query persons. (b) Person search results of the proposed method. For each query, we select its top-ranked matching boxes. The green borders indicate correct matchings while the red ones indicate wrong.
Reference
If you want to use our dataset or codes, please feel free to contact us (sli [at] ee.cuhk.edu.hk).
Please reference the following paper for more details:
- T. Xiao, S. Li, B. Wang, X. Wang and L. Lin. End-to-End Deep Learning for Person Search, arXiv
pdf