Unsupervised Activity Perception by Hierarchical Bayesian Model
Note: the provided video examples are compressed with XviD MPEG-4 Codec. To install the Xvid codec, you can download codec from ffdshow-tryouts (http://ffdshow-tryout.sourceforge.net/) or www.xvid.org.
Introduction
The goal of this work is to understand activities and interactions in a complicated scene, e.g. a crowded traffic scene (see video examples), a busy train station (see video examples) or a shopping mall. In such scenes individual objects are often not easily tracked because of frequent occlusions among objects, and many different types of activities often occur simultaneously. Nonetheless, we expect a visual surveillance system to: (1) find typical single-agent activities (e.g. car makes a U-turn) and multi-agent interactions (e.g. vehicles stop waiting for pedestrians to cross the street) in this scene, and provide a summary; (2) label short video clips in a long sequence by interaction, and localize different activities involved in an interaction; (3) show abnormal activities, e.g. pedestrians cross the road outside the crosswalk; and abnormal interactions, e.g. jay-walking (people cross the road while vehicles pass by); (4) support queries about an interaction that has not yet been discovered by the system. Ideally, a sysmte would learn models of the scene to answer such questions in an unsupervised way.
Our Approach
To answer these challenges for visual surveillance systems, we must determine: how to compute low-level visual features, and how to model activities and interactions. Our approach is shown in Figure 1. We compute local motion, which are moving pixels indexed by discretized location and direction, as our low-level visual features, avoiding difficult tracking problems in crowded scenes. We do not adopt global motion features, because in our case multiple activities occur simultaneously and we want to separate singleagent activities from interactions. Word-document analysis is then performed by quantizing local motion into visual words and dividing the long video sequence into short clips as documents. We assume that visual words caused by the same atomic activity often co-exist in video clips (documents) and that interaction is a combination of atomic activities occuring in the same clip. Given this problem structure, we employ a hierarchical Bayesian approach, in which atomic activities are modeled as distributions over low-level visual features, and interactions are modeled as distributions over atomic activities. Under this model, surveillance tasks like clustering video clips and abnormality detection have a nice probabilistic explanation. Because our data is hierarchical, a hierarchical model can have enough parameters to fit the data well while avoiding overfitting problems, since it is able to use a population distribution to structure some dependence into the parameters. A detailed description of this work can be found in [1] and [2].
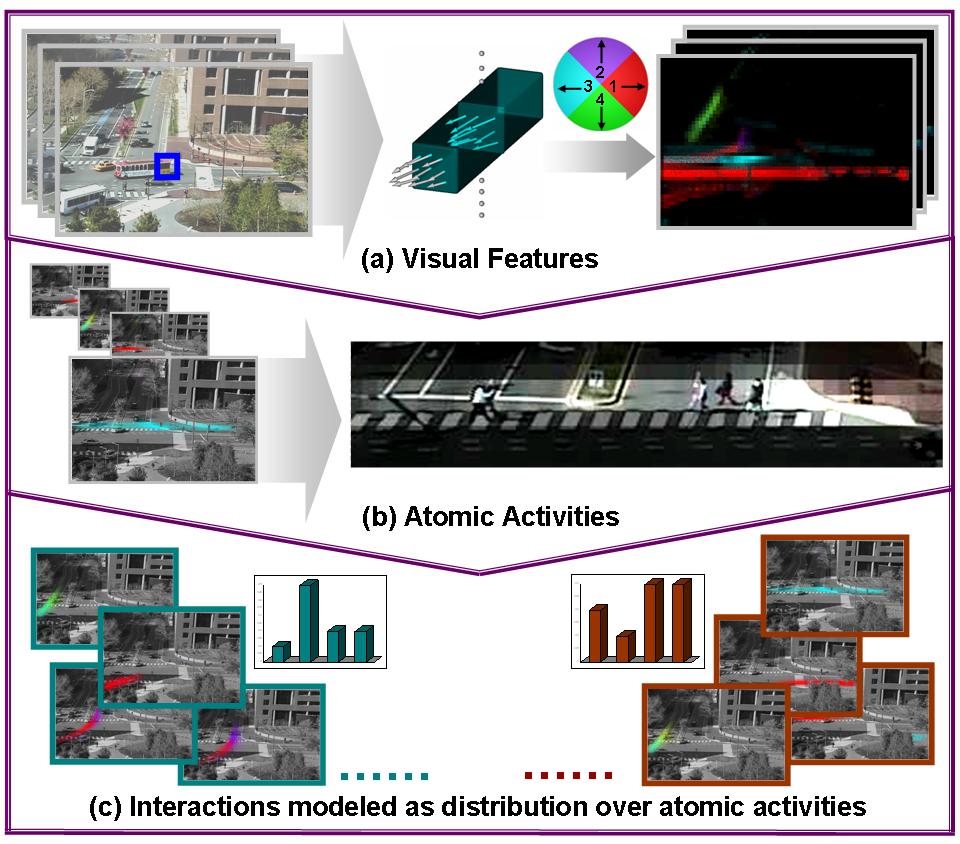
Figure 1. System Diagram
Discover Atomic Activities and Interactions
Using our hierarchical Bayesian mixture model, 29 atomic activities are discovered in an unsupervised way. Figure 3 plots their distributions over local motions. They reveal some interesting activities in the scene, such as pedestrians cross the road, vehicles stop, vehicles make turns, etc. At the same time, the short video clips are grouped into five clusters, which represent five different interactions: traffic in vertical direction, vehicles from g make rught turn, pedestrians cross the roads, vehicles from left make left turn, and traffic in horizontal direction. Figure 3 plots their distributions over 29 topics.

Figure 2. 29 discovered atomic activities in an unsupervised way, showing their distributions on motion features. The four colors represent four discretized motion directions.
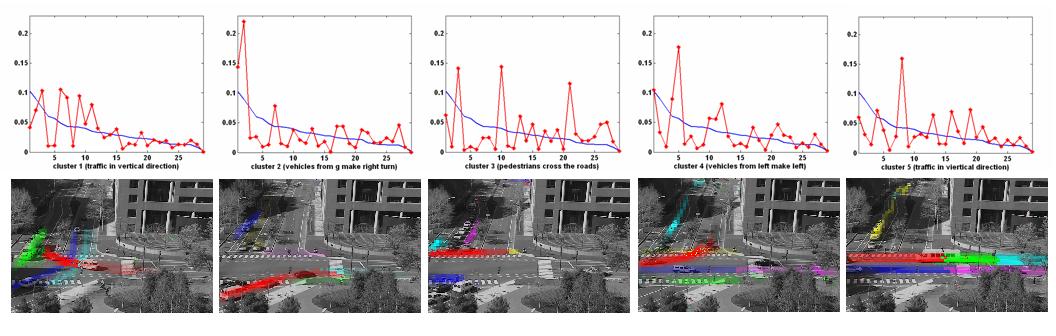
Figure 3. Short video clips are grouped into five clustered, which represent five different interactions. In the first row, we plot the interaction distributions over 29 atomic activities. In the second row, we show a vidoe clip as an example for each kind of interactions and mark the motions of the five largest atomic activities in that video clip.
Video Segmentation
Given a long video sequence, we can segment it based on different types of interactions. Our models provide a natural way to complete this task in an unsupervised manner since video clips are automatically separated into clusters (interactions) in our model. See video segmentation results here.

Figure 4. Video segmentation. Colors represent different interactions.
Activity Detection
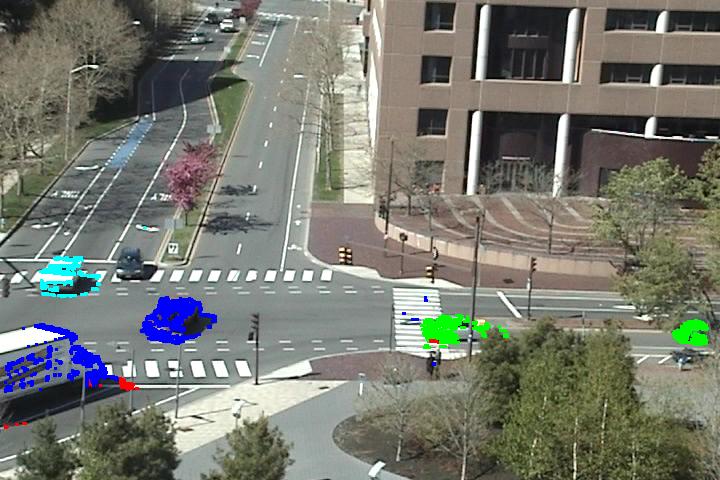
We also want to localize different types of atomic activities happening in the video. Since in our hierarchical Bayesian models, each moving pixel is labeled as one of the atomic activities, activity detection becomes straightforward. In Figure 5, we choose five ten seconds long video clips as examples of the five different interactions, and show the activity detection results on them. See video results here (1 2 3 4 5).
 |
 |
 |
 |
 |
Figure 5. Activity detection. Colors represent different atomic activities. However since there are so many atomic activities, we cannot use a uniform color scheme to represent all of them. In this Figure, the same color in different video clips may indicate different activities. Clip 1 has atomic activities 1 (green), 3 (cyan), 6 (blue) (see these atomic activities in Figure 7). Clip 2 has atomic activities 2 (cyan), 13 (blue). Clip 3 has atomic activities 15 (cyan), 7 (blue), 21 (red). Clip 4 has atomic activities 1 (red), 5 (blue), 7(green), 12 (cyan), 15 (yellow). Clip 5 has atomic activities 8 (red), 16 (cyan), 17 (magenta), 20 (green).
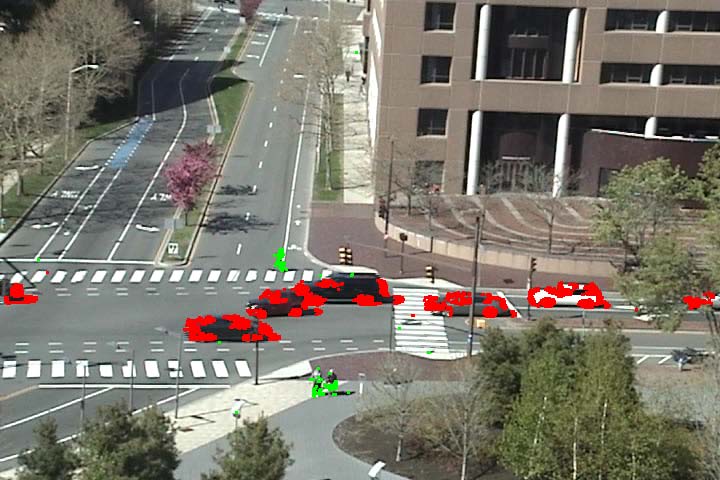
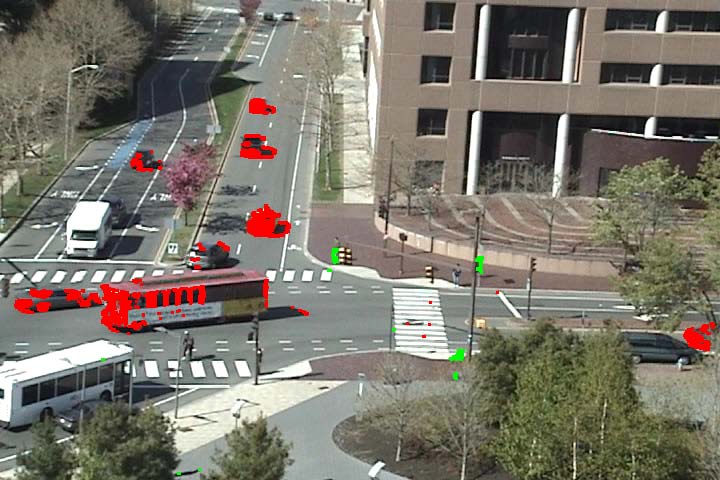
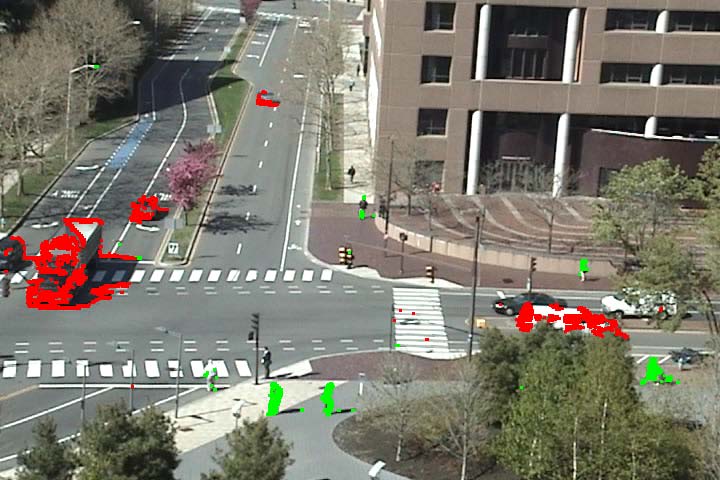
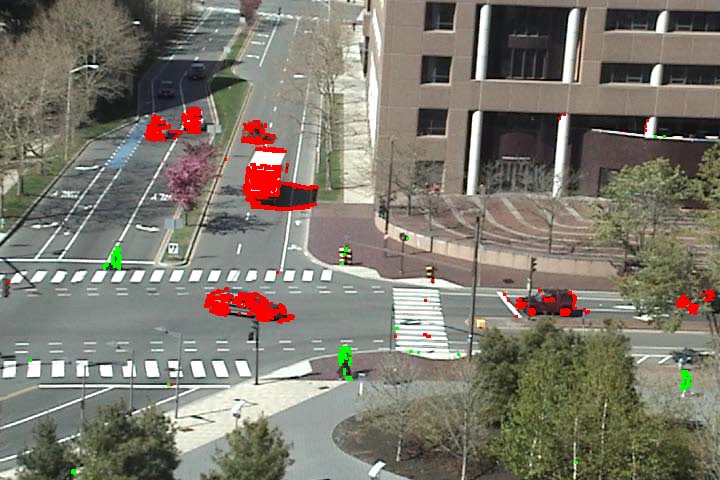
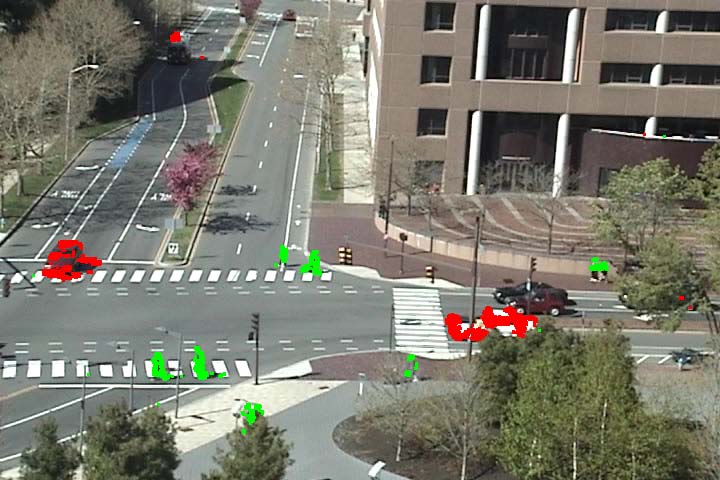
As an extension of activity detection, we can detect vehicles and pedestrians based on motions. It is observed that the vehicle motions and pedestrian motions are well separated among atomic activities. However, the user first needs to label each of the discovered atomic activities as being related to vehicles or pedestrians. Then we can classify the moving pixels into vehicles and pedestrians based on their atomic activity labels. See video result here.
 |
 |
 |
 |
 |
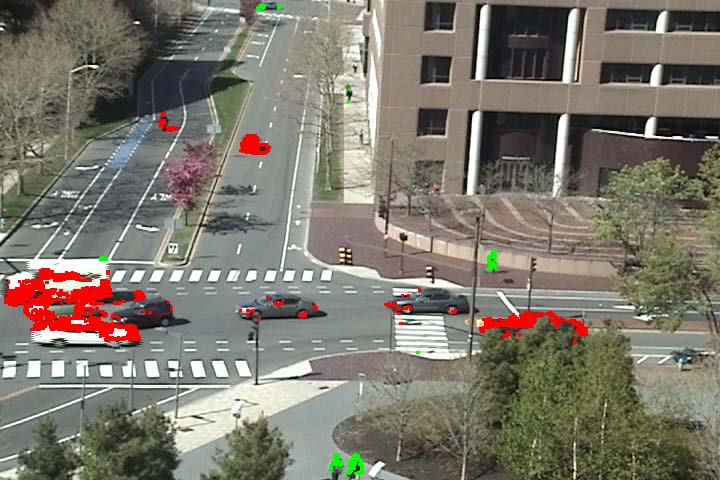 |
Figure 6 Vehicle and pedestrian detection. Vehicle motions are marked by red color and pedestrian motions are marked by green color.
Abnormality Detection
In visual surveillance, detecting abnormal video clips and localizing abnormal activities in the video clip are of great interest. Under the Bayesian models, abnormality detection has a nice probabilistic explanation by the marginal likelihood of every video clip or motion rather than by comparing similarities between samples. See vidoe results here (1 2 3 4 5).
 |
 |
 |
 |
 |
Figure 7. Abnormality detection. We show the top five video clips with the highest abnormality (lowest likelihood). In each video clip, we highlight the regions with motions of high abnormality.
High-Level Semantic Query
In our framework, it is convenient to use atomic activities as tools to query for interactions of interest. For example, suppose a user wants to detect jay-walking. This is not automatically discovered by the system as a typical interaction. Thus, the user simply picks topics involved
in the interaction, e.g. topic 6 and 13, i.e. “pedestrians walk on crosswalk a from right to left
(topic 13) while vehicles are approaching in vertical direction (topic 6)”, and specifies the query
distribution q (q(6) = q(13) = 0:5 and other mixtures are zeros). The topic distributions {p_{j}} of video clips in the data set match with the query distribution using relative entropy between q and p_{j}. Figure 8 shows the result of querying examples of “pedestrians walk on crosswalk a from
right to left while vehicles are approaching in vertical direction”. All the video clips are sorted
by matching similarity. The true instance will be labeled 1, otherwise it is labeled as 0. There
are in total 18 jay-walking instances in this data set, and they are all found among the top 37
examples out of the 540 clips in the whole video sequence. The top 12 retrieval results are all correct. See video results here.

Figure 8. Query result of jay-walking. (a) We pick two atomic activities (topic 6 and 13) involved in the interaction jay-working. (b) A query distribution is drawn with large weights on topic 6 and 13 and zeros weights on other topics. (c) An example of jay-walk retrieval. We have more video examples in the supplementary results. (d) shows the top 40 retrieval results. If the video clip is correct, it is labeled as 1 otherwise 0.
Results on the Train Station Scene
We also test our models on a train station scene (see video examples) . Figure 9 shows the 22 discovered atomic activities from a one hour video sequence. These atomic activities explain people going up or coming down the escalators, or passing by in different ways.
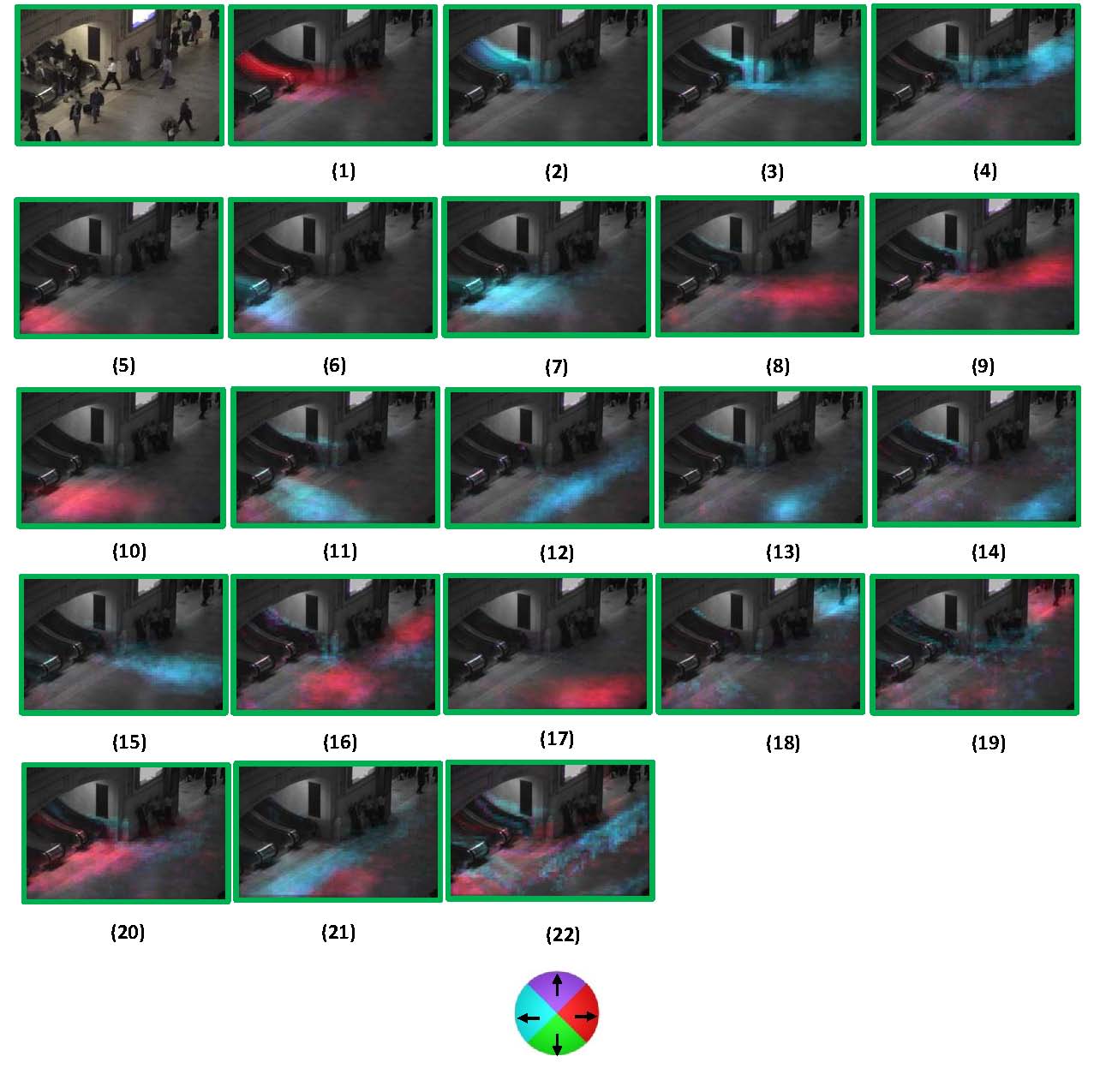
Figure 9 Motion distributions of discovered atomic activities on a train station scene. The motion is quantized into four directions represented by four colors.
[1] X. Wang, X. Ma and E. Grimson, “Unsupervised Activity Perception by Hierarchical Bayesian Models,” in Proceedings of IEEE Computer Society Conference on Computer Vision and Patter Recognition (CVPR) 2007. [PDF].
[2] X. Wang, X. Ma and E. Grimson, "Unsupervised Activity Perception in Crowded and Complicated Scenes Using Hierarchical Bayesian Models," submitted to IEEE Transactions on Pattern Analysis and Machine Intelligence (PAMI) [PDF].